
Node.js Unearthed: Exploring the Ecosystem
Harnessing the Full Potential of JavaScript for Server-Side Development


Table of contents
- Single Thread vs Multi Thread Systems
- Single Threaded System
- Multi Threaded System
- Is NodeJS Single Threaded or MultiThreaded ?
- Event Loop: The Heart of NodeJS 💖
- Blocking vs Non Blocking I/O
- CallStack
- CallStack with Non-Blocking I/O :
- CallStack With Blocking I/O :
- Thread Pool
- EventQueue
- EventLoop
- Child Processes in NodeJS
- exec()
- execFile()
- spawn()
- fork()
Node.js, being a server-side JavaScript runtime, empowers developers to build scalable and efficient applications. One of the features that makes Node.js particularly versatile is its ability to work with child processes.
In this Article, We will go through working and aspects of ChildProcesses and they allow you to execute external scripts or commands, enabling parallelism and interaction with other languages and InterProcessCommunication(IPC).
Single Thread vs Multi Thread Systems
Single Threaded System
Single Threaded Systems are those in which only one instruction or thread is processed by CPU at given interval of time , Single Threaded Systems executes instructions in sequential manner.
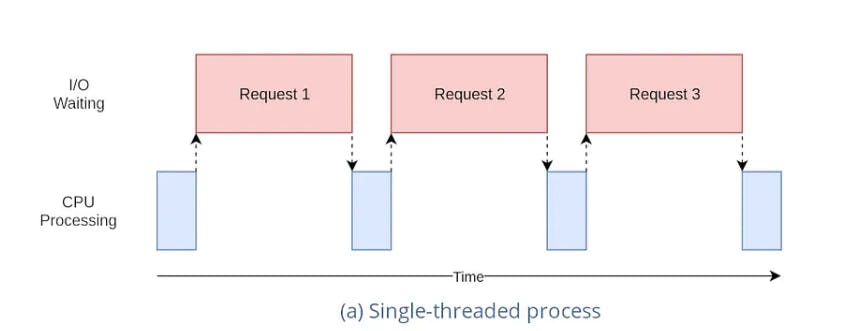
These systems have only one main thread of execution and they have less concurrency and scalability requirements .
Multi Threaded System
Multi-threaded programs utilize multiple threads to handle tasks concurrently, potentially improving performance and responsiveness. They are well-suited for applications that involve complex computations, I/O operations, or tasks that can run independently .
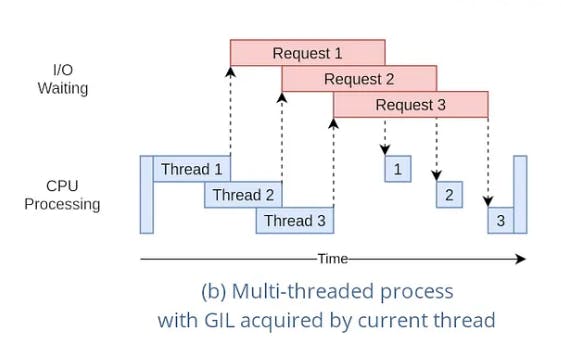
Multi-threaded programs excel in scenarios with computationally intensive tasks or applications that can benefit from parallel processing. They can enhance overall system performance and responsiveness .
Is NodeJS Single Threaded or MultiThreaded ?
The NodeJS is "Single Threaded" i.e. It uses only main thread for its execution . The JavaScript Code of NodeJS Application is executed on main thread only but other side Processes and asynchronous tasks are handled by Event Loop , Worker Threads and ChildProcesses without creation of extra thread .
In conclusion, Node.js’s “single-threaded” nature can be misleading at first glance. While it does use a single thread for JavaScript execution, it excels at handling concurrent connections and I/O operations . Let's see What The Hack Event Loop is and How It Contributes In Concurrency .
Event Loop: The Heart of NodeJS 💖
Event Loop in NodeJS is responsible for the Non-Blocking I/O operations , concurrency and parallelism . There are various aspects in event loop such as Follows :
Blocking and Non-Blocking I/O
CallStack
libUV and Thread Pool
Event Loop
Stages In Event Loop
Blocking vs Non Blocking I/O
In sequential execution of processes , If execution of upcoming processes is halted or blocked due to current executing process . This halting can occur due to User Input , File Read/Write operation this is called "Blocking I/O"
In Non-Blocking I/O all processes occur sequentially and there is no halting and blocking .
CallStack
CallStack with Non-Blocking I/O :
CallStack is data structure apart from event loop which stores function calls in our program in form of stack . It has LIFO(Last In First Out) implementation . It is Single Threaded System
Let's Consider Below Code for understanding CallStack
function first(){
console.log("I am the First Function")
}
function second(){
console.log("I am the Second Function")
}
function third(){
console.log("I am the Third Function")
}
first()
second()
third()
// Ouput of Code :
// I am the First Function
// I am the Second Function
// I am the Third Function
We have three functions first() second() third() and this is non-blocking I/O . CallStack for this code will be like this

First of All , When our code runs then it takes functions from our code for execution as we can see here we have three functions for execution . Initially we have empty callstack and no output on terminal .
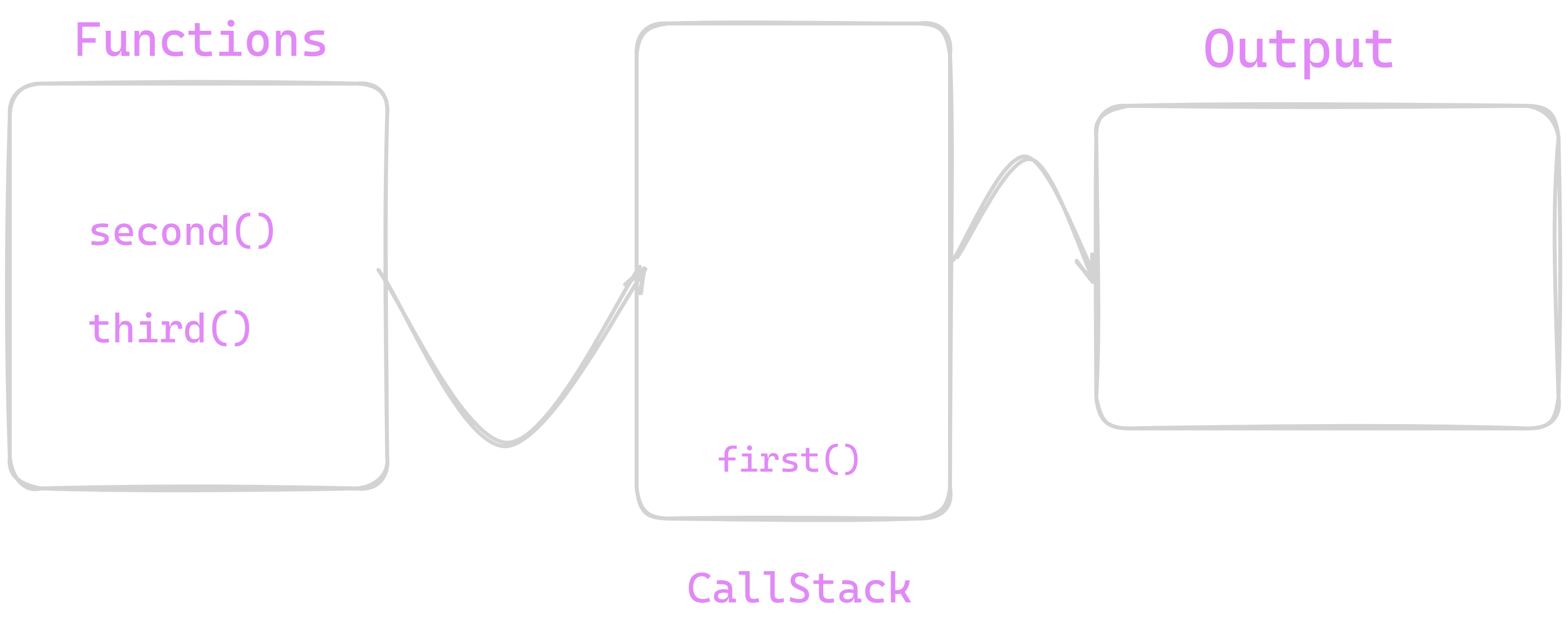
Now , we can see first() function is pushed to callstack for execution . Before pushing function callstack it is verified that function is Blocking or not and if it is NonBlocking function i.e. it do not contains any File I/O or async nature or any callback or timers etc. if it is nonblocking then pushed on callstack for execution otherwise It is handed over to special section called "Thread Pool ".
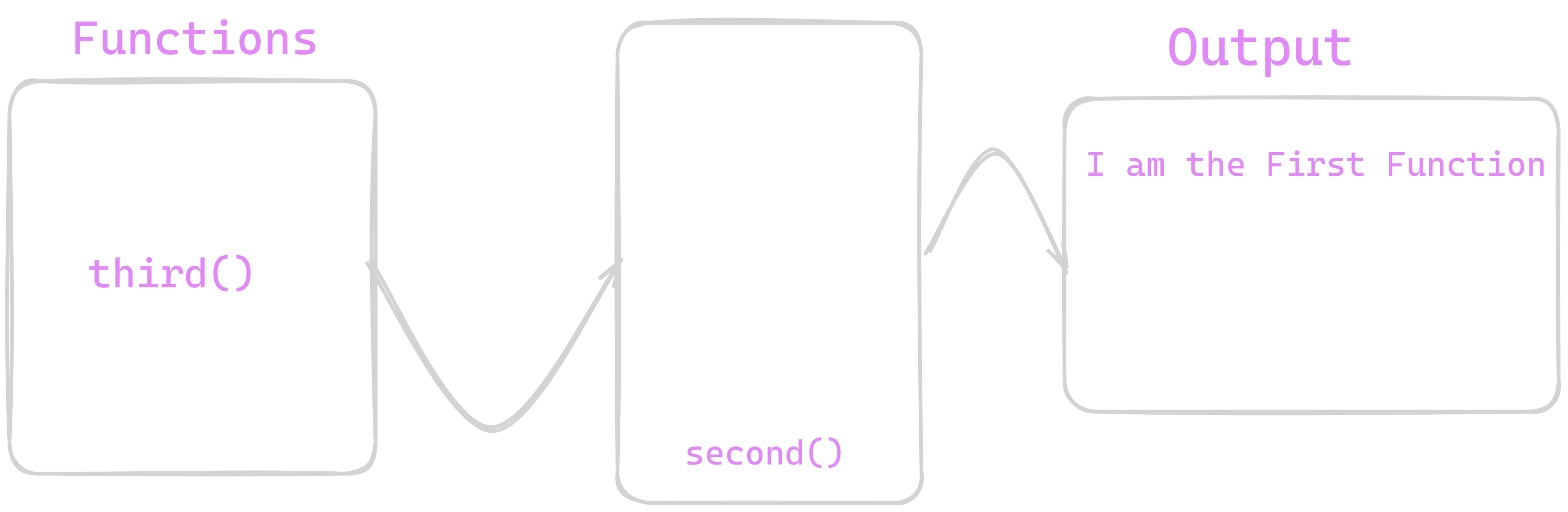
Now , as first() was non-blocking function so it was stacked on callstack and we see its output on console . further second() function was stacked on callstack now it will execute second function and prints its output and will stack third() function on stack and will prints output of third process. Now we will see how it works with Blocking I/O
CallStack With Blocking I/O :
Let's Look code below how callsatck executes with Blocking I/O
COPY
COPY
const fs =require('fs');
function first() {
console.log("I am the First Function")
}
function four() {
console.log("This is Fourth Function");
setTimeout(()=>{
console.log("This is timeout function")
},500)
}
function second() {
console.log("I am Second function");
}
function third() {
console.log("I am the Third Function")
}
first()
four()
second()
third()
// Output of Code :
//I am the First Function
//This is Fourth Function
//I am Second function
//I am the Third Function
// Below statement will print after 500 milliseconds
//This is timeout function
When Our Code will start executing we know it will stack first() function on call stack and will print it's output . After that it will push four() on call stack now we will call stack from this function
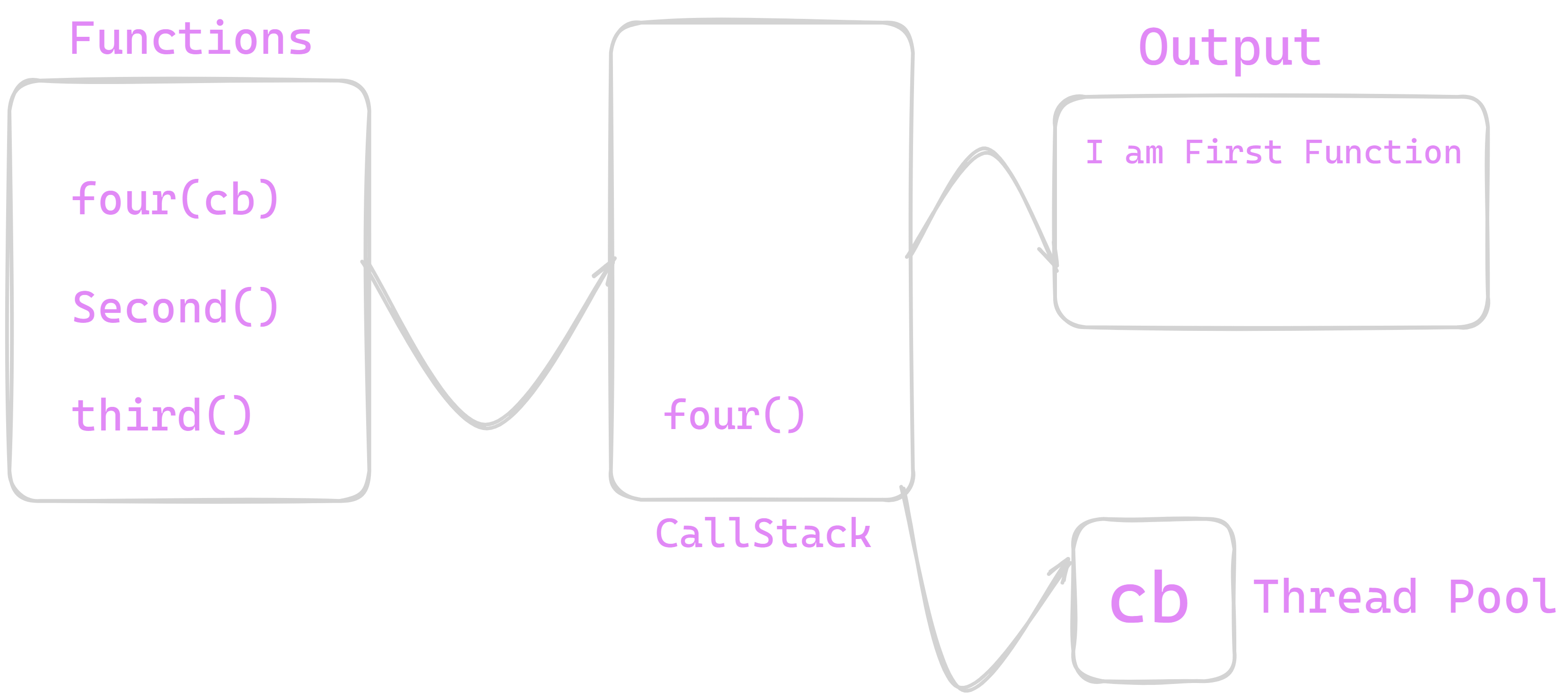
We know that four() function is Blocking function as it contains settimeout() as its callback function so what will occur only four() body without settimeout() will be executed and out settimeout() which is callback function will be handed over to section called "Thread Pool" and then further second() and third() functions are stacked on stack .
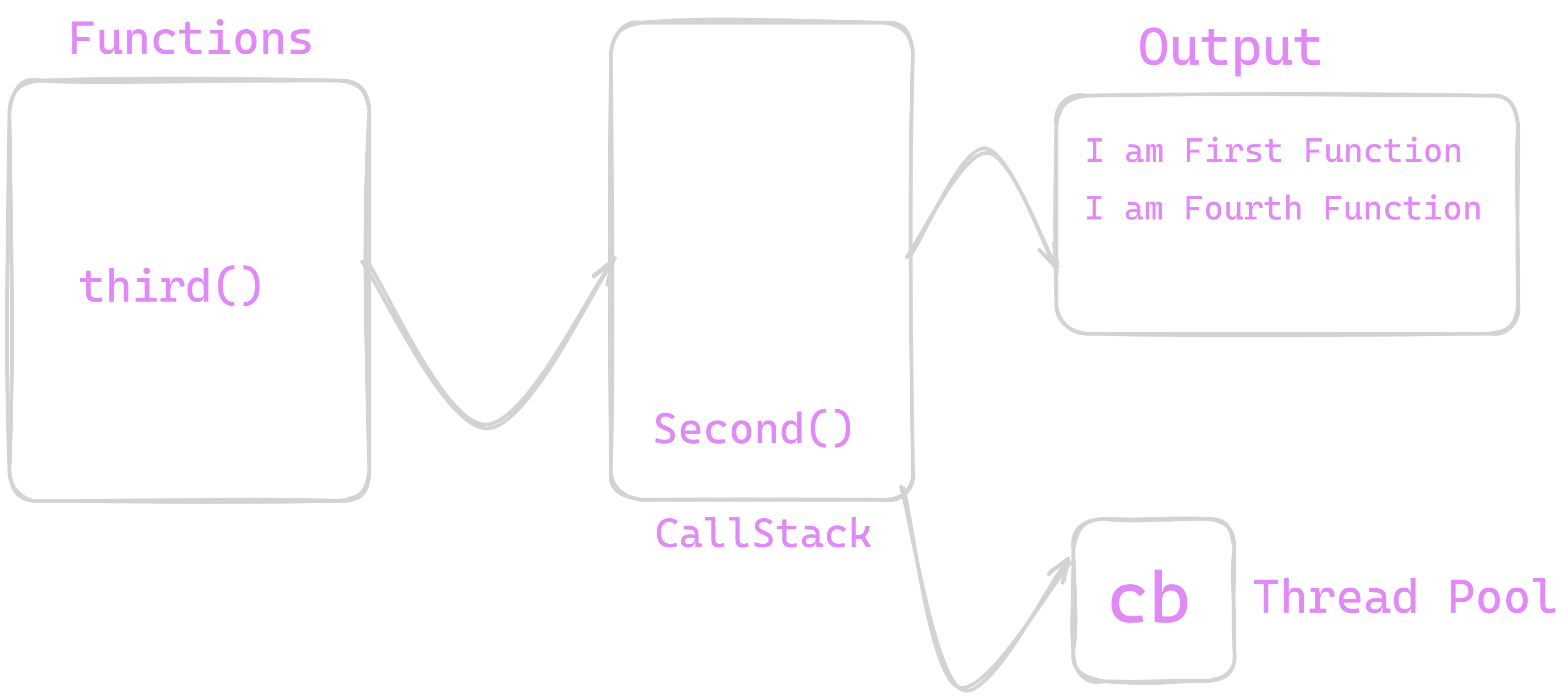
We will see what occurs to that callback function in upcoming section . After four() function second() function is stacked over callstack and it is executed and output is printed on output console . Similar thing happens with third() function and its output is printed . Up to this our callstack should look as shown below.
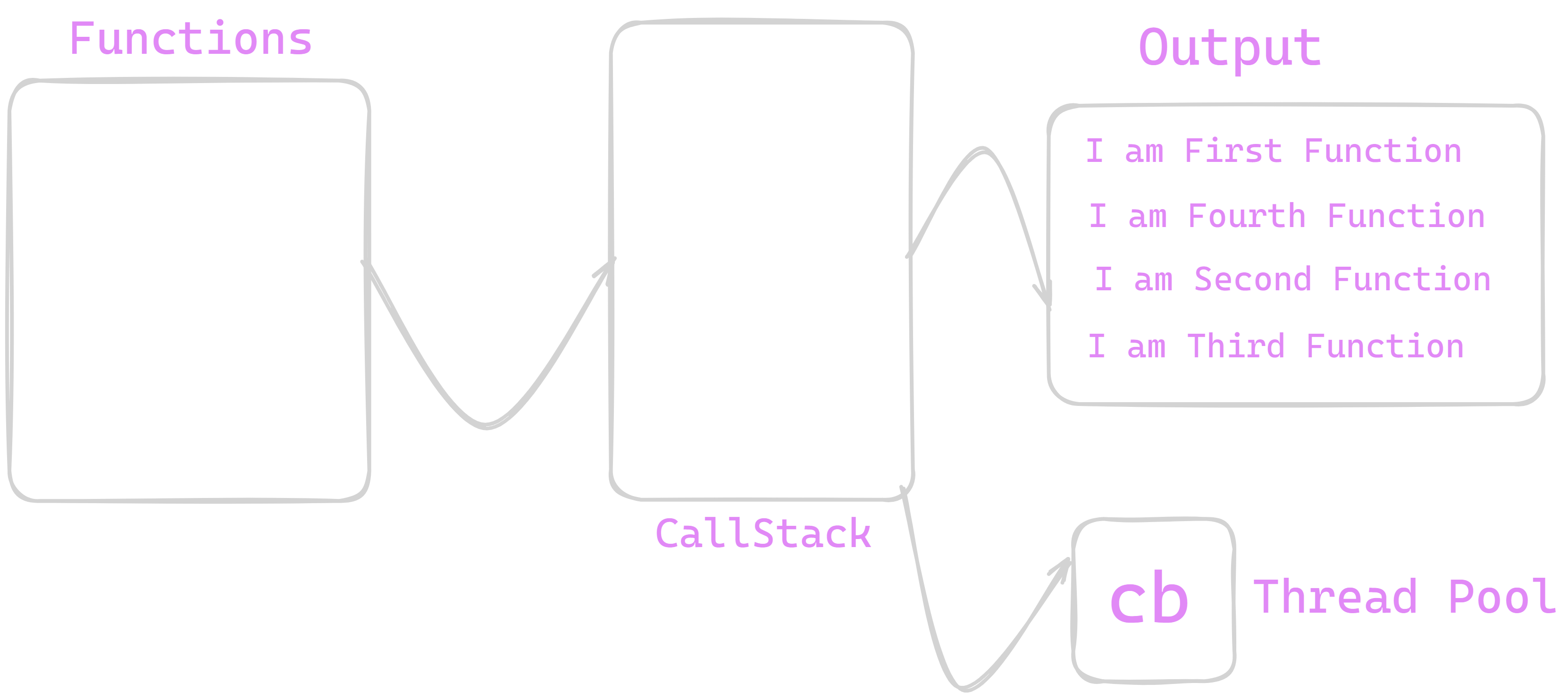
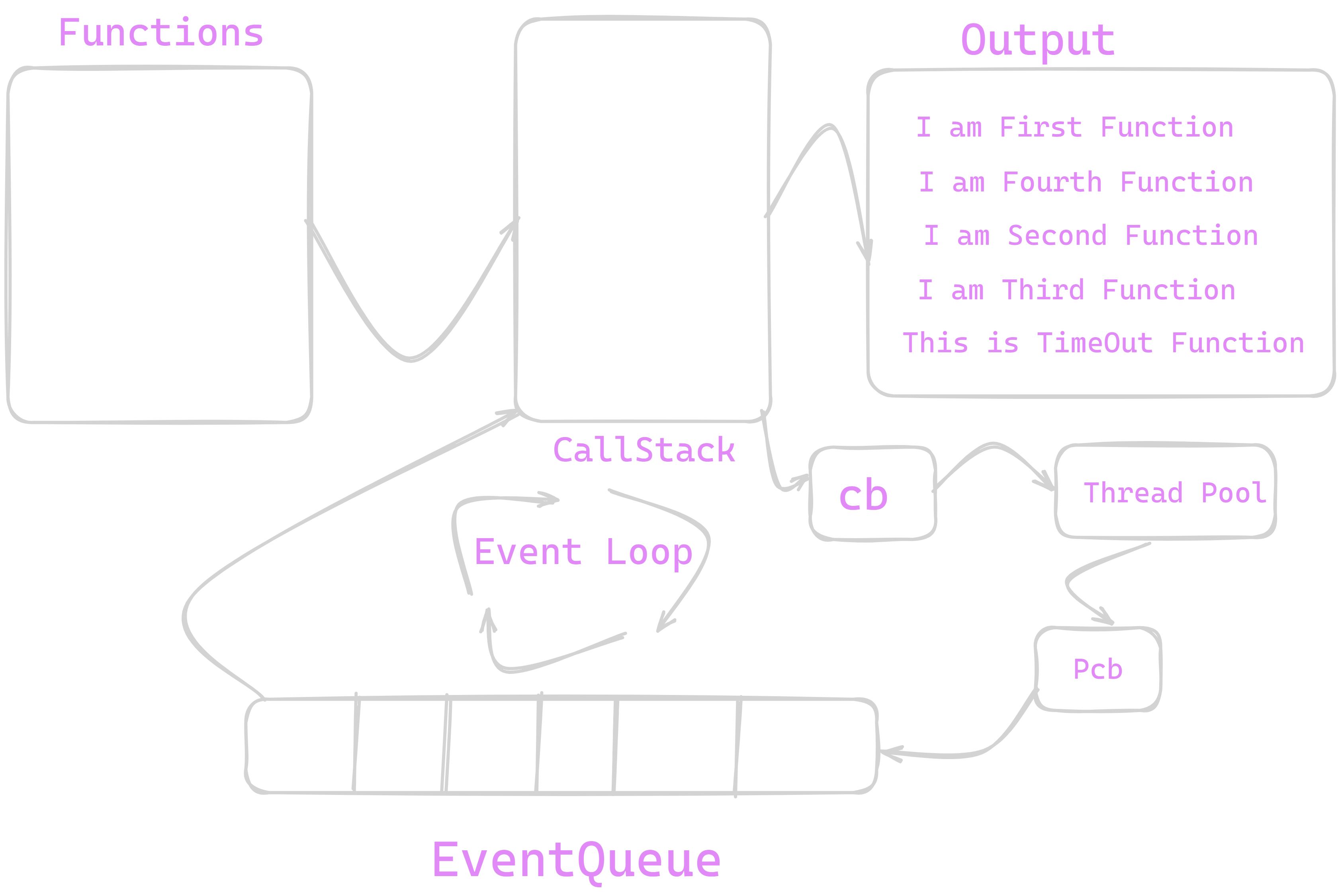
We can see our callstack is empty but we are remaining our callback function and its output . To execute our Remaining Callback function we require ThreadPool and EventQueue .
Thread Pool
Thread pool is Internal Implementation of NodeJS where we have 4 main working threads which performs different async operations such as File I/O , Timer function handlers , async processes . These Pools are multi threaded and they are implemented in C / C++ languages . The most popular library for this is libUV . They processes callback function and make them ready for Event Queue . The Final Output of ThreadPool is special format of function. This special format of function is queued over Event Queue. Execution of callback functions is implemented after completing all non-blocking functions.
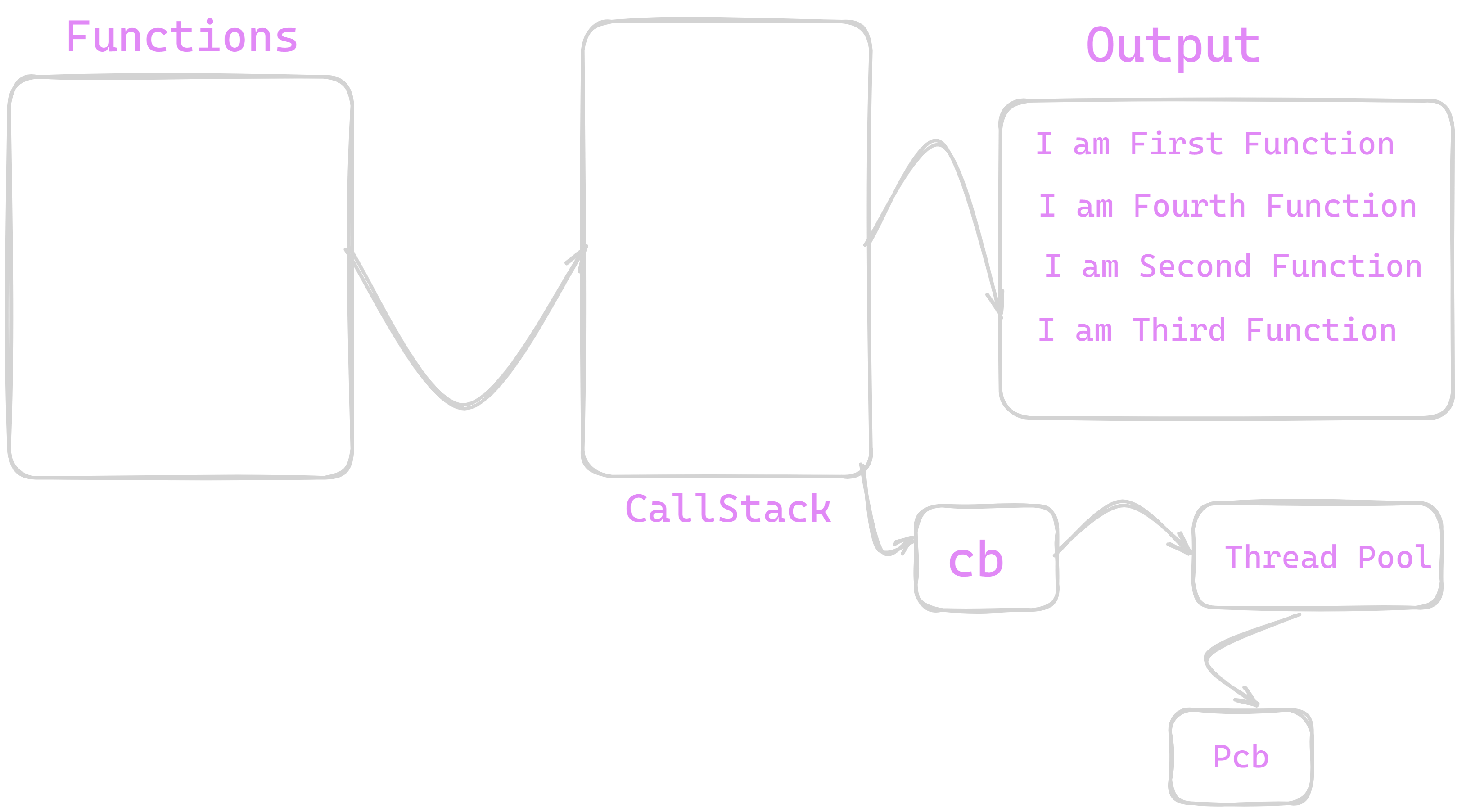
In this state , Our callback function cb() is now converted into Pcb() which is special format of function which Event Queue can understand . This is Pcb() is queued on EventQueue.
EventQueue
It is CORE NodeJS implementation which forms queue of various functions from ThreadPool . It is Single threaded in nature and works on principle of FIFO(First In First Out). It has various stages in between for the processing of function .These function in EventQueues are dequeued and then given to callstack for Implementation .
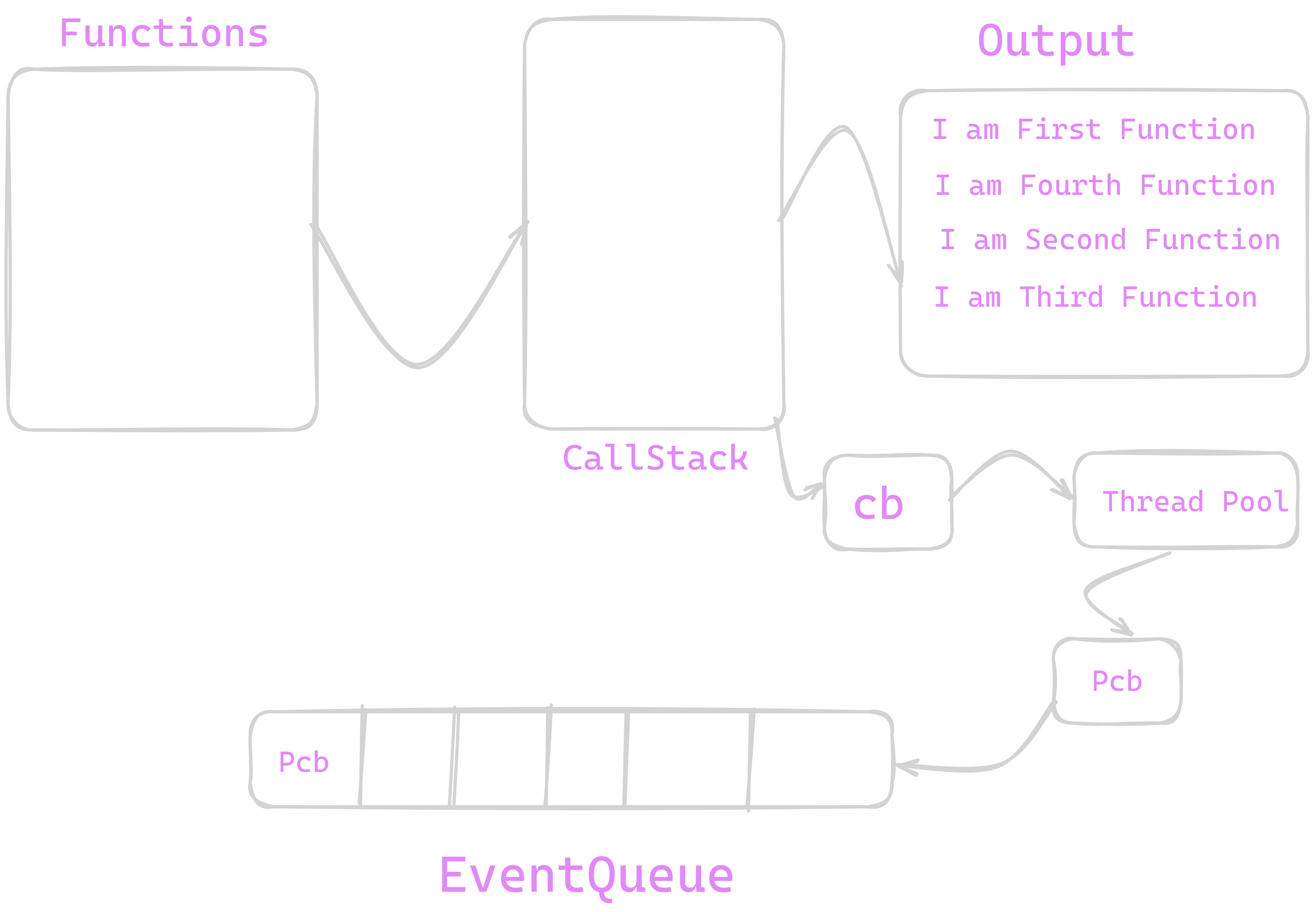
Now we can see our Pcb() is queued on EventQueue . as our function is settimeout() and our time parameter was 500 milliseconds therefore EventQueue will dequeue our Pcb() after 500 milliseconds and it will gone to callstack and from callstack it will be popped out .
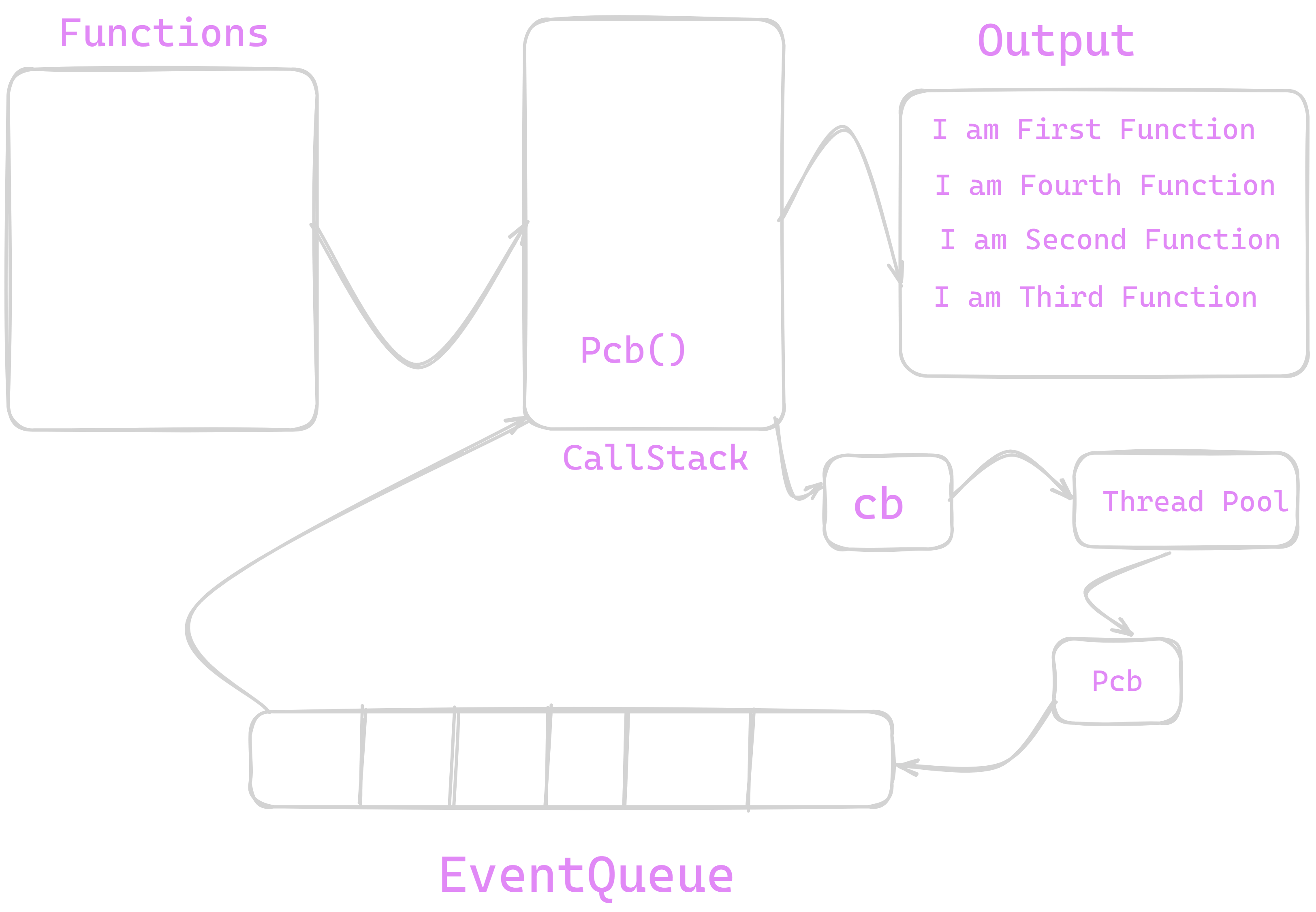
Now Pcb() is on callstack it will get implemented and output is printed on console . This is how blocking functions can be executed by call Stack .
EventLoop
An Event loop is a programming construct or mechanism that allows a program to efficiently handle and respond to external events or asynchronous tasks .
EventLoop runs when we run NodeJS program and It runs until program termination . It first check callstack executes all non-blocking functions in it first and then registers callbacks in ThreadPool then queues callbacks in eventloop , again check callstack empty and then dequeue them and push it to callstack . The process of continuously checking Callstack and EventQueue called "EventLoop" .
EventLoop isSingleThreaded that is main reason Why NodeJs is Single Threaded .

Note : You Can use console.trace() function to check the callstack of execution
Child Processes in NodeJS
Node.js internally works through single process . If consider scenarios when there is need of some CPU intensive tasks such as calculation sum of million numbers , processing graphics etc. we can generate processes which will be executing these tasks without disturbing main NodeJS process and these generated processes are called as "ChildProcesses"
ChildProcesses are way for scalability and parallelism in NodeJs . There are main four Ways in which we can implement childprocess .
exec()
execFile()
spawn()
fork()
exec()
The exec() method in the child_process module of Node.js is used to run shell commands. It allows you to execute arbitrary shell commands from within your Node.js application.
For Coding purposes of Childprocesses we require "child_process" Module of NodeJS .First of all , we have to destructure exec() method from child_processes module . exec(command,(err,stdout,stderr)) this is syntax of exec() function , we have to pass command as first parameter in this function and second parameter is callback function with three parameters {err,stdout,stderr} . Let's understand these one by one
err : This is error before running child process
stdout : This is output of process
stderr : This is error after child process is executed
Let's see below code for exec()
const { exec } = require('child_process');
exec('ls', (error, stdout, stderr) => {
if (error) {
console.error(`Error: ${error.message}`);
return;
}
console.log(`stdout: ${stdout}`);
if (stderr) {
console.log(`stderr: ${stderr}`);
}
});
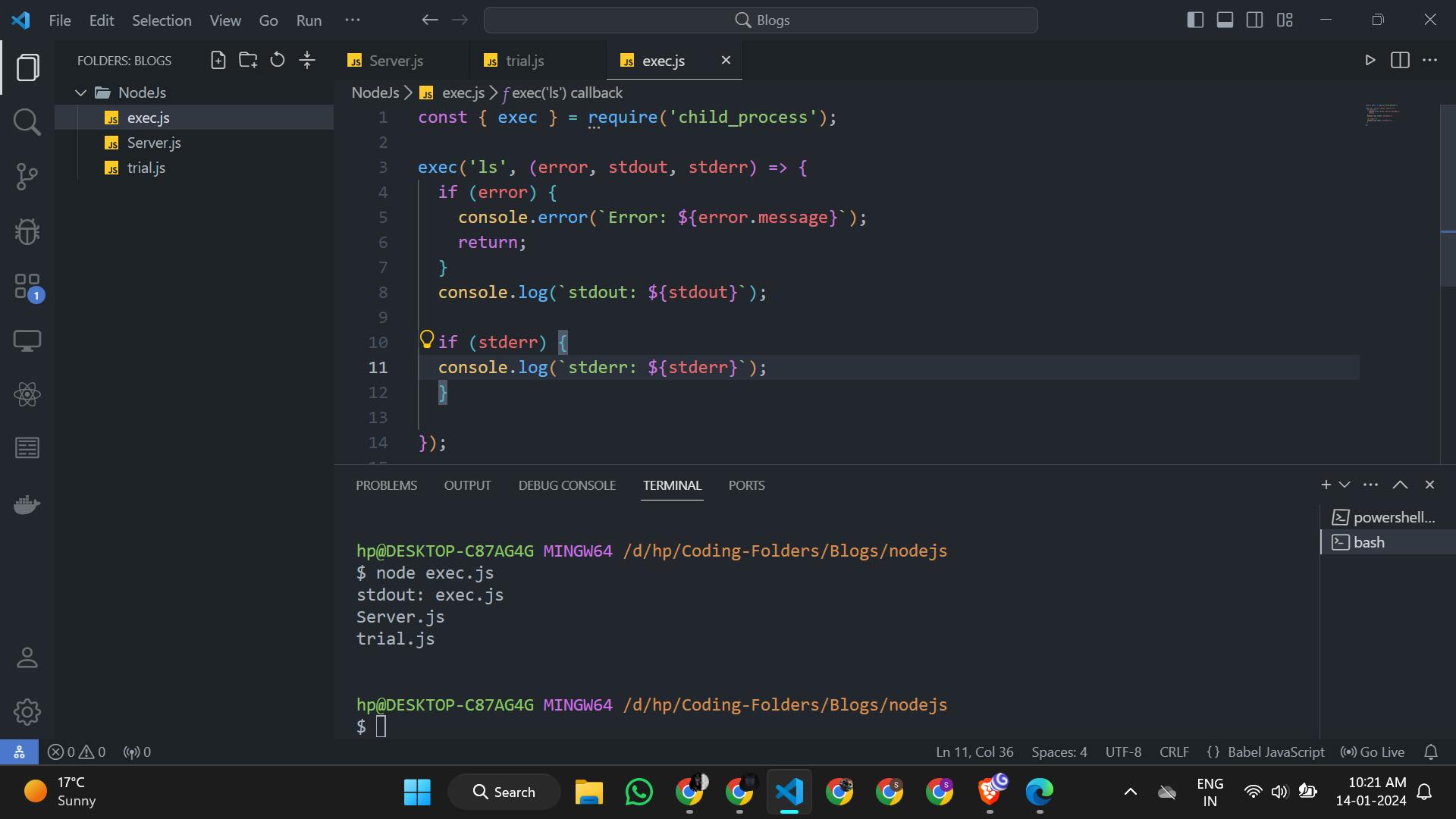
Here , we can see I have executed ls command and it has given me all files in directory .
One problem with exec() method is that it uses buffer for storage and if we run very big task to exec() method then it fails . Lets See with code
const { exec } = require('child_process');
exec('find /', (error, stdout, stderr) => {
if (error) {
console.error(`Error: ${error.message}`);
return;
}
console.log(`stdout: ${stdout}`);
if (stderr) {
console.log(`stderr: ${stderr}`);
}
});
// Here we Have Used find / command for exec() which is quite memory
// Consuming task .
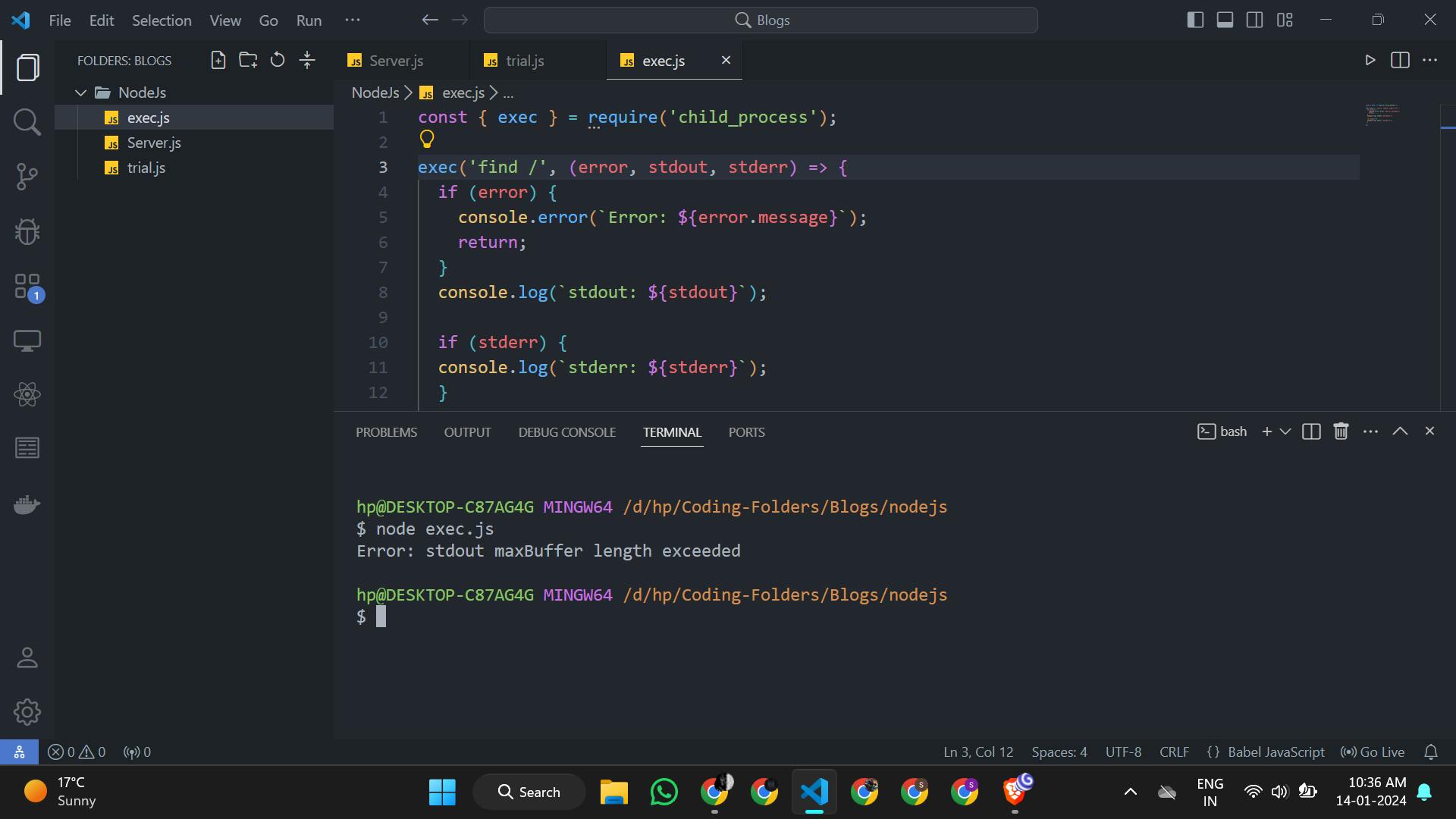
As you can see , In Error we can see maxBuffer Length is exceeded . It is overcame by spawn() we will see it next section of blog . Execution of exec() make use of shell and shell scripts .
execFile()
The execFile() method in Node.js is part of the child_process module and is used to run an executable file or script in a child process. This method is similar to exec(), but it is specifically designed for executing binary executables or scripts without involving a shell. Using execFile() can be considered more secure than exec() when dealing with user inputs, as it helps prevent shell injection vulnerabilities.
Let's see code for execFile() method
// Code for main file
const { execFile } = require('child_process');
execFile('node',["./demo.js"], (error, stdout, stderr) => {
if (error) {
console.error(`Error: ${error.message}`);
return;
}
console.log(`stdout: ${stdout}`);
if (stderr) {
console.log(`stderr: ${stderr}`);
}
});
// This is Demo.js File
console.log("Hello From Demo")
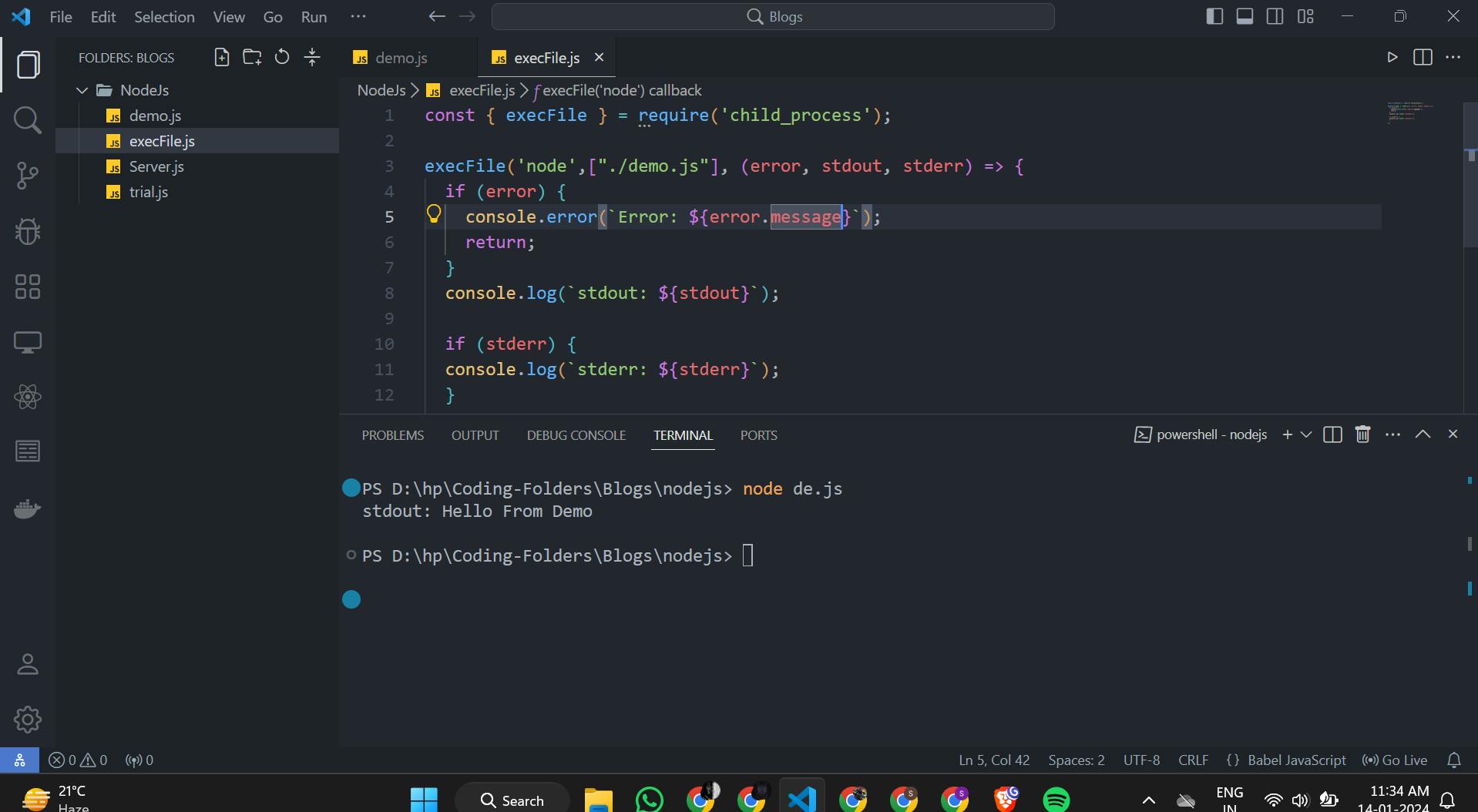
execFile() also use Buffer for its implementation but it is more secure than exec() method . It also fails in execution of CPU intensive tasks .
spawn()
The spawn method in the child_process module of Node.js is used to launch a new process and execute a command within that process. It provides a more flexible and lower-level approach compared to the exec and execFile methods. The spawn method is particularly useful when dealing with long-running processes, as it allows you to interact with the spawned process through streams .
Let's understand code for spawn() method
const { spawn } = require('child_process');
const ls = spawn('ls', ['-l']);
ls.stdout.on('data', (data) => {
console.log(`stdout: ${data}`);
});
ls.stderr.on('data', (data) => {
console.error(`stderr: ${data}`);
});
ls.on('close', (code) => {
console.log(`child process exited with code ${code}`);
});
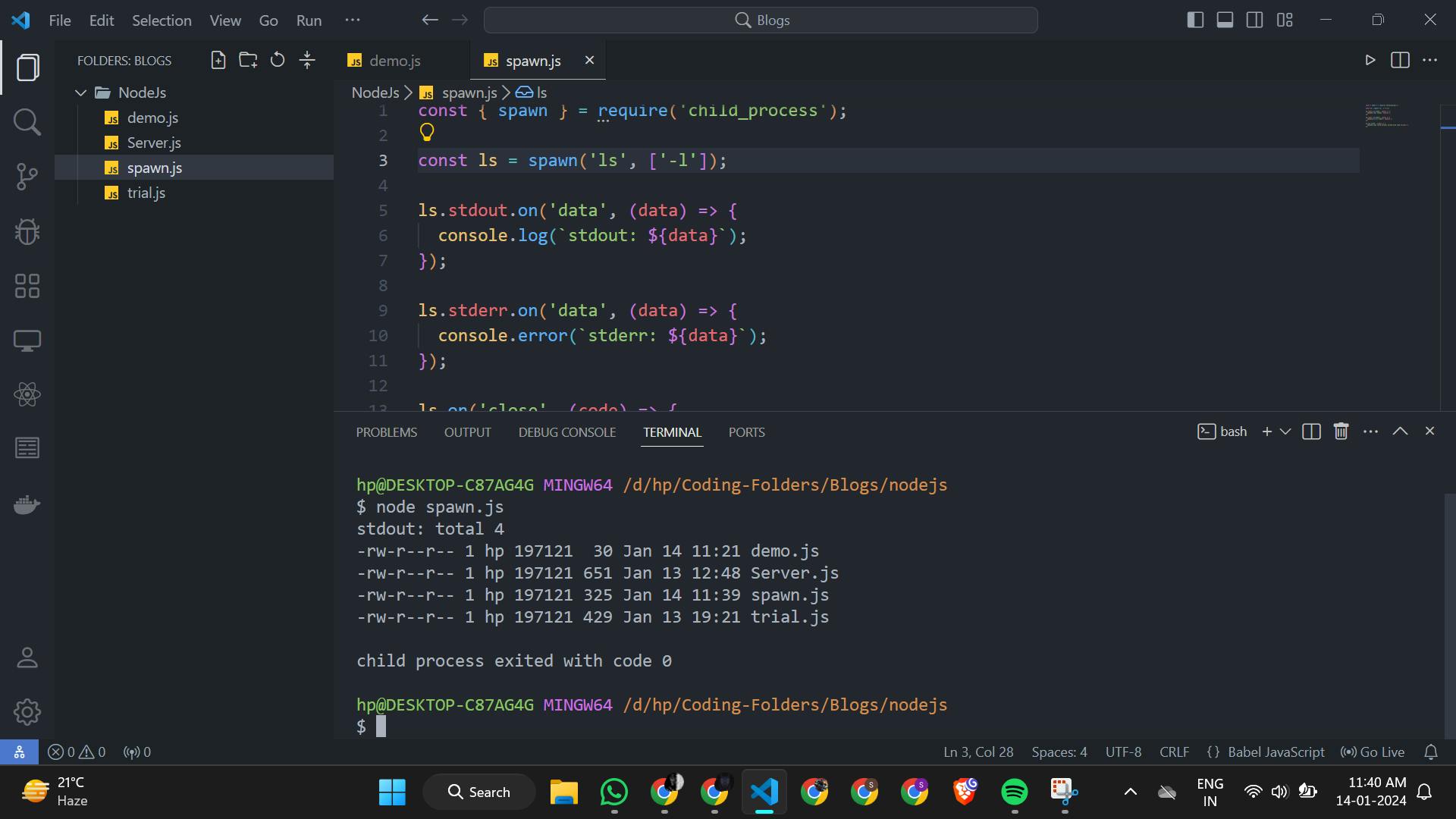
We can see here on giving command of ls it has given us list of files in current directory and now lets check for find / command how it behaves
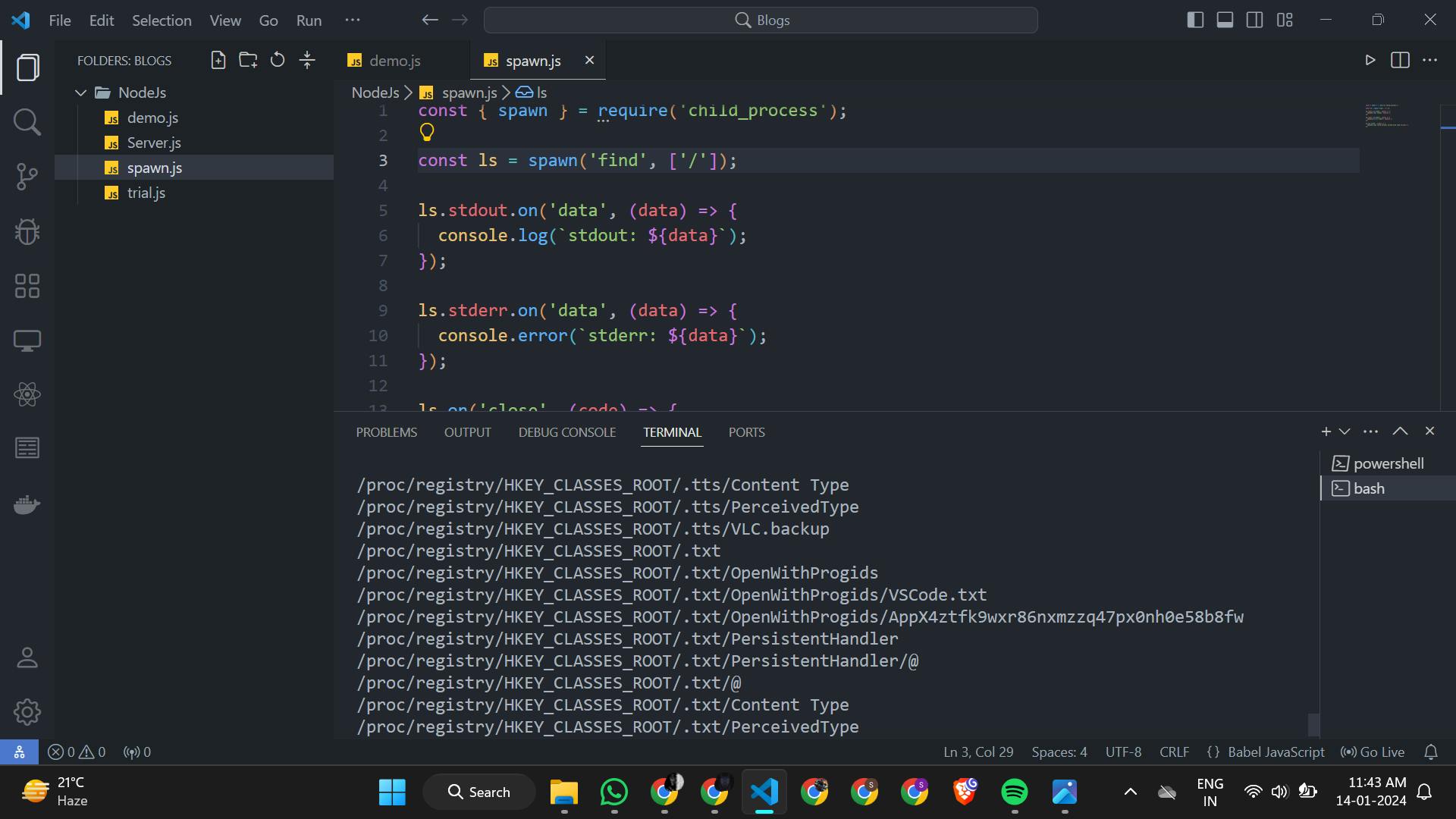
We can see here on giving command for find / it does not given error . spawn() uses streams for its implementation so , it is more efficient than exec() and execFile() in more Complex tasks .
fork()
The fork method in Node.js is a specialized form of the spawn method in the child_process module. It is specifically designed for creating child processes that run separate instances of the V8 JavaScript engine. The primary use case for fork is to execute separate Node.js scripts as child processes with their own event loops.
Lets see code for it
// parent.js
const { fork } = require('child_process');
const child = fork('child.js');
child.on('message', (message) => {
console.log('Received message from child:', message);
});
child.send({ hello: 'world' });
// child.js
process.on('message', (message) => {
console.log('Received message from parent:', message);
});
process.send({ foo: 'bar' });
fork() is specially used when we have to perform Inter-Process Communication(IPC).
Note : Above codes of childprocesses will not work in somecases if you are using powershell terminal in VScode , You Have to change it to Git Bash for this .
That's a wrap! Do comment down your learnings or doubts below in the comments section and also suggest me topics for next blogs.
Thank you For Reading !
This blog has been written by Aditya Suryawanshi (LinkedIn, GitHub, Hashnode, Twitter)